
 Photo given by the writers– created making use of Gemini.
Photo given by the writers– created making use of Gemini.
For much of us, expert system (AI) has actually entered into daily life, and the price at which we appoint formerly human functions to AI systems reveals no indicators of decreasing. AI systems are the critical components of several innovations– e.g., self-driving autos, wise metropolitan preparation, electronic aides– throughout an expanding variety of domain names. At the core of much of these innovations are self-governing representatives– systems developed to act upon part of people and choose without straight guidance. In order to act properly in the real life, these representatives should can accomplishing a variety of jobs regardless of potentially uncertain ecological problems, which usually needs some type of artificial intelligence (ML) for attaining flexible practices.
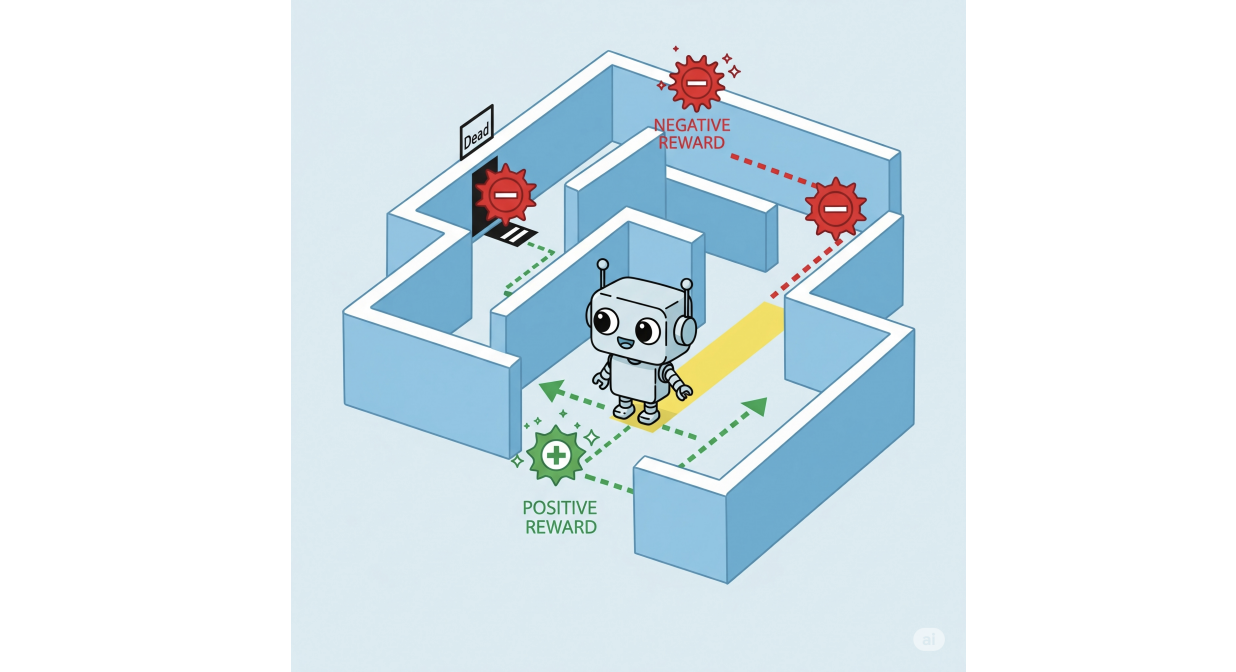
Support understanding (RL) [6] attracts attention as an effective ML strategy for educating representatives to accomplish optimum practices in stochastic atmospheres. RL representatives discover by connecting with their setting: for each activity they take, they obtain context-specific benefits or fines. In time, they discover practices that makes the most of the anticipated benefits throughout their runtime.
Photo given by the writers– created making use of Gemini.
RL representatives can grasp a wide array of intricate jobs, from winning computer game to managing cyber-physical systems such as self-driving autos, usually exceeding what professional people can. This optimum, reliable practices, nevertheless, if left completely uncontrolled, might end up being repulsive and even unsafe to the people it influences. This encourages the considerable research study initiative in secure RL, where specialized methods are established to make sure that RL representatives fulfill details security demands. These demands are usually revealed in official languages like straight temporal reasoning ( LTL), which expands timeless (true/false) reasoning with temporal drivers, enabling us to define problems like “something that should constantly hold”, or “something that needs to ultimately happen”. By integrating the flexibility of ML with the accuracy of reasoning, scientists have actually established effective approaches for educating representatives to act both properly and securely.
Nevertheless, security isn’t every little thing. Certainly, as RL-based representatives are progressively offered functions that either change or carefully communicate with people, a brand-new obstacle occurs: guaranteeing their habits is likewise certified with the social, lawful and honest standards that framework human culture, which usually surpass straightforward restrictions ensuring security. For instance, a self-driving cars and truck could flawlessly comply with security restrictions (e.g. staying clear of accidents), yet still embrace actions that, while practically secure, go against social standards, showing up peculiar or impolite when driving, which could trigger various other (human) chauffeurs to respond in hazardous methods.
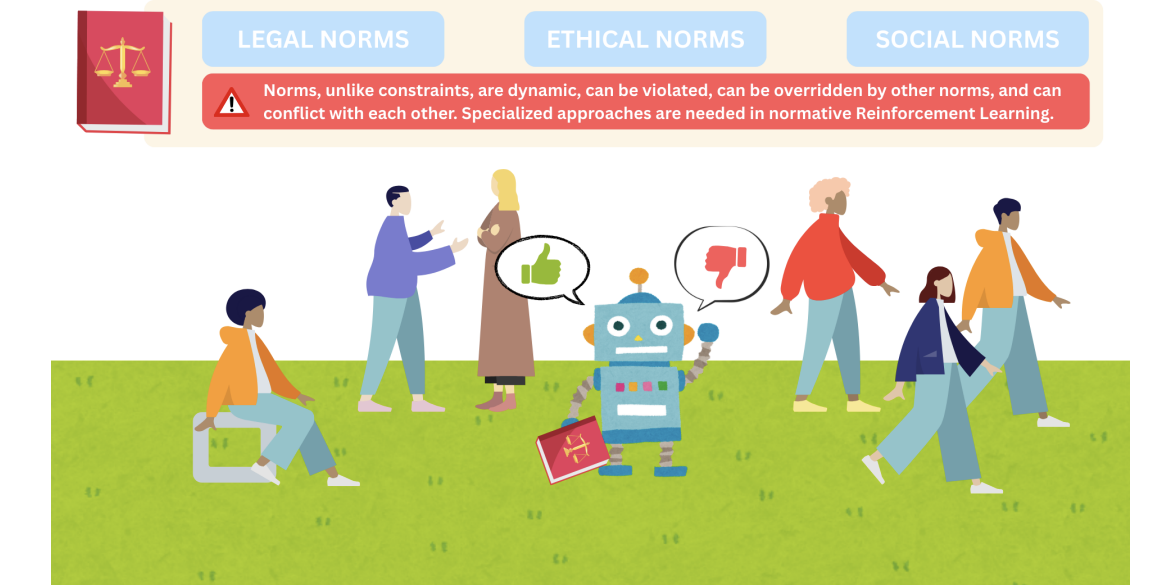
Standards are usually revealed as commitments (” you should do it”), authorizations (” you are allowed to do it”) and restrictions (” you are restricted from doing it”), which are not declarations that can be real or incorrect, like timeless reasoning solutions. Rather, they are deontic ideas: they define what is right, incorrect, or acceptable– optimal or appropriate practices, as opposed to what is really the situation. This subtlety presents numerous challenging characteristics to thinking concerning standards, which several reasonings (such as LTL) battle to take care of. Also every-day normative systems like driving policies can include such issues; while some standards can be extremely straightforward (e.g., never ever go beyond 50 kph within city limitations), others can be extra intricate, as in:
- Constantly preserve 10 meters in between your lorry and the lorries before and behind you.
- If there are much less than 10 meters in between you and the lorry behind you, you ought to reduce to place even more area in between on your own and the lorry before you.
( 2) is an instance of a contrary-to-duty responsibility (CTD), a commitment you should comply with particularly in a scenario where an additional main responsibility (1) has actually currently been broken to, e.g., make up or lower damages. Although examined thoroughly in the areas of normative thinking and deontic reasoning, such standards can be troublesome for several standard secure RL approaches based upon implementing LTL restrictions, as was gone over in[4]
Nevertheless, there are techniques for secure RL that reveal extra prospective. One noteworthy instance is the Limiting Screw strategy, presented by De Giacomo et al.[2] Called after a tool made use of in the Celebrity Wars cosmos to suppress the habits of androids, this technique affects a representative’s activities to line up with defined policies while still enabling it to seek its objectives. That is, the limiting screw changes the habits an RL representative discovers to ensure that it likewise values a collection of specs. These specs, revealed in a variation of LTL (LTLf [3]), are each coupled with its very own incentive. The main concept is straightforward yet effective: together with the benefits the representative gets while checking out the setting, we include an extra incentive whenever its activities please the equivalent spec, pushing it to act in manner ins which line up with private security demands. The task of details benefits to private specs enables us to design extra difficult characteristics like, e.g., CTD commitments, by appointing one incentive for complying with the main responsibility, and a various incentive for complying with the CTD responsibility.
Still, problems with modeling standards linger; as an example, several (otherwise most) standards are conditional. Think about the responsibility specifying “if pedestrians exist at a pedestrian going across, after that the close-by lorries should quit”. If a representative were awarded whenever this policy was completely satisfied, it would certainly likewise obtain benefits in circumstances where the standard is not really effective. This is because, in reasoning, a ramification holds likewise when the antecedent (” pedestrians exist”) is incorrect. Therefore, the representative is awarded whenever pedestrians are not about, and could discover to lengthen its runtime in order to build up these benefits for properly not doing anything, as opposed to effectively seeking its desired job (e.g., getting to a location). In [5] we revealed that there are circumstances where a representative will certainly either neglect the standards, or discover this “laziness” habits, regardless of which compensates we select. Therefore, we presented Normative Limiting Screws (NRBs), an advance towards implementing standards in RL representatives. Unlike the initial Limiting Screw, which urged conformity by giving extra benefits, the normative variation rather penalizes standard infractions This layout is influenced by the Andersonian sight of deontic reasoning [1], which deals with commitments as policies whose infraction always causes a permission. Therefore, the structure no more counts on enhancing appropriate habits, yet rather implements standards by ensuring that infractions bring concrete fines. While efficient for taking care of complex normative characteristics like conditional commitments, contrary-to-duties, and exemptions to standards, NRBs depend on experimental incentive adjusting to carry out standard adherence, and for that reason can be unwieldy, particularly when attempting to solve disputes in between standards. Furthermore, they call for re-training to fit standard updates, and do not provide themselves to warranties that optimum plans lessen standard infractions.
Our payment
Structure on NRBs, we present Ordered Normative Restraining Bolts (ONRBs), a structure for leading support finding out representatives to abide by social, lawful, and honest standards while attending to the constraints of NRBs. In this technique, each standard is dealt with as a purpose in a multi-objective support understanding (MORL) issue. Reformulating the issue by doing this enables us to:
- Confirm that when standards do not problem, a representative that discovers optimum practices will certainly lessen standard infractions with time.
- Express connections in between standards in regards to a ranking system defining which standard needs to be focused on when a problem takes place.
- Usage MORL methods to algorithmically figure out the required size of the penalties we appoint such that it is guarantied that as long as a representative discovers optimum practices, standards will certainly be broken just feasible, focusing on the standards with the highest possible ranking.
- Suit modifications in our normative systems by “shutting off” or “reactivating” details standards.
We examined our structure in a grid-world setting influenced by method video games, where a representative discovers to gather sources and provide them to marked locations. This configuration enables us to show the structure’s capacity to take care of the complicated normative circumstances we kept in mind above, together with straight prioritization of clashing standards and standard updates. For example, the number listed below
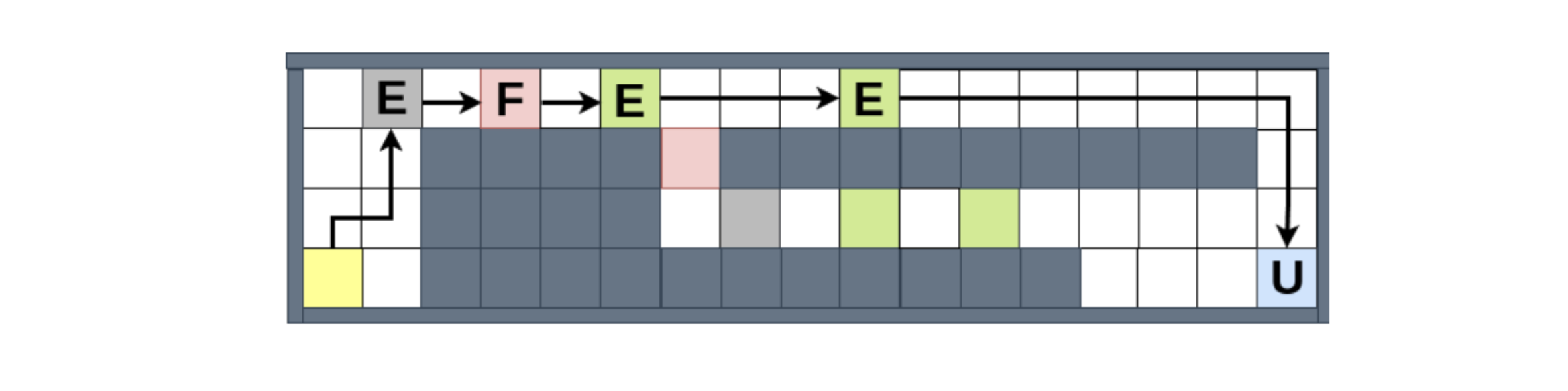
presents exactly how the representative deals with standard disputes, when it is both obliged to (1) stay clear of the unsafe (pink) locations, and (2) get to the marketplace (blue) location by a particular due date, intending that the 2nd standard takes concern. We can see that it selects to go against (1) when, due to the fact that or else it will certainly be stuck at the start of the map, not able to meet (2 ). However, when offered the opportunity to go against (1) once again, it selects the certified course, despite the fact that the breaking course would certainly permit it to gather even more sources, and for that reason extra benefits from the setting.
In recap, by integrating RL with reasoning, we can construct AI representatives that do not simply function, they function right.
This job won a differentiated paper honor at IJCAI 2025 Review the paper completely: Combining MORL with restraining bolts to learn normative behaviour, Emery A. Neufeld, Agata Ciabattoni and Radu Florin Tulcan.
Recognitions
This research study was moneyed by the Vienna Scientific Research and Innovation Fund (WWTF) job ICT22-023 and the Austrian Scientific Research Fund (FWF) 10.55776/ COE12 Collection of Quality Bilateral AI.
Referrals
[1] Alan Ross Anderson. A decrease of deontic reasoning to alethic modal reasoning. Mind, 67( 265 ):100– 103, 1958.
[2] Giuseppe De Giacomo, Luca Iocchi, Marco Favorito, and Fabio Patrizi.Foundations for restraining bolts: Reinforcement learning with LTLf/LDLf restraining specifications In Process of the worldwide meeting on automated preparation and organizing, quantity 29, web pages 128– 136, 2019.
[3] Giuseppe De Giacomo and Moshe Y Vardi.Linear temporal logic and linear dynamic logic on finite traces In IJCAI, quantity 13, web pages 854– 860, 2013.
[4] Emery Neufeld, Ezio Bartocci, and Agata Ciabattoni.On normative reinforcement learning via safe reinforcement learning In PRIMA 2022, 2022.
[5] Emery A Neufeld, Agata Ciabattoni, and Radu Florin Tulcan.Norm compliance in reinforcement learning agents via restraining bolts In Lawful Expertise and Info Solution JURIX 2024, web pages 119– 130. Iphone Press, 2024.
[6] Richard S. Sutton and Andrew G. Barto. Support understanding– an intro. Flexible calculation and artificial intelligence MIT Press, 1998.
发布者:Agata Ciabattoni,转转请注明出处:https://robotalks.cn/ijcai2025-distinguished-paper-combining-morl-with-restraining-bolts-to-learn-normative-behaviour-2/