
Meta today presented V-JEPA 2, a 1.2-billion-parameter globe design educated mainly on video clip to sustain understanding, forecast, and preparation in robot systems. Improved the Joint Embedding Predictive Design (JEPA), the design is developed to aid robotics and various other “AI representatives” browse unknown atmospheres and jobs with minimal domain-specific training.
V-JEPA 2 complies with a two-stage training procedure all without extra human note. In the initial, self-supervised phase, the design gains from over 1 million hours of video clip and 1 million pictures, catching patterns of physical communication. The 2nd phase presents action-conditioned understanding making use of a tiny collection of robotic control information (regarding 62 hours), enabling the design to consider representative activities when forecasting results. This makes the design functional for preparing and closed-loop control jobs.
Meta stated it has actually currently checked this brand-new design on robotics in its laboratories. Meta records that V-JEPA 2 does well on usual robot jobs like and pick-and-place, making use of vision-based objective depictions. For easier jobs such as choice and location, the system creates prospect activities and examines them based upon anticipated results. For harder jobs, such as getting an item and positioning it in the best area, V-JEPA2 utilizes a series of aesthetic subgoals to lead actions.
In interior examinations, Meta stated the design revealed appealing capability to generalise to brand-new items and setups, with success prices varying from 65% to 80% on pick-and-place jobs in formerly undetected atmospheres.

” Our company believe globe designs will certainly bring in a brand-new age for robotics, making it possible for real-world AI representatives to aid with tasks and physical jobs without requiring expensive quantities of robot training information,” stated Meta’s principal AI researcher Yann LeCun.
Although V-JEPA 2 comes along over previous designs, Meta AI stated there stays an obvious space in between design and human efficiency on these criteria. Meta recommends this indicate the requirement for designs that can run throughout several timescales and techniques, such as integrating sound or responsive info.
To examine progression in physical understanding from video clip, Meta is additionally launching the complying with 3 criteria:
- IntPhys 2: examines the design’s capability to compare literally possible and doubtful situations.
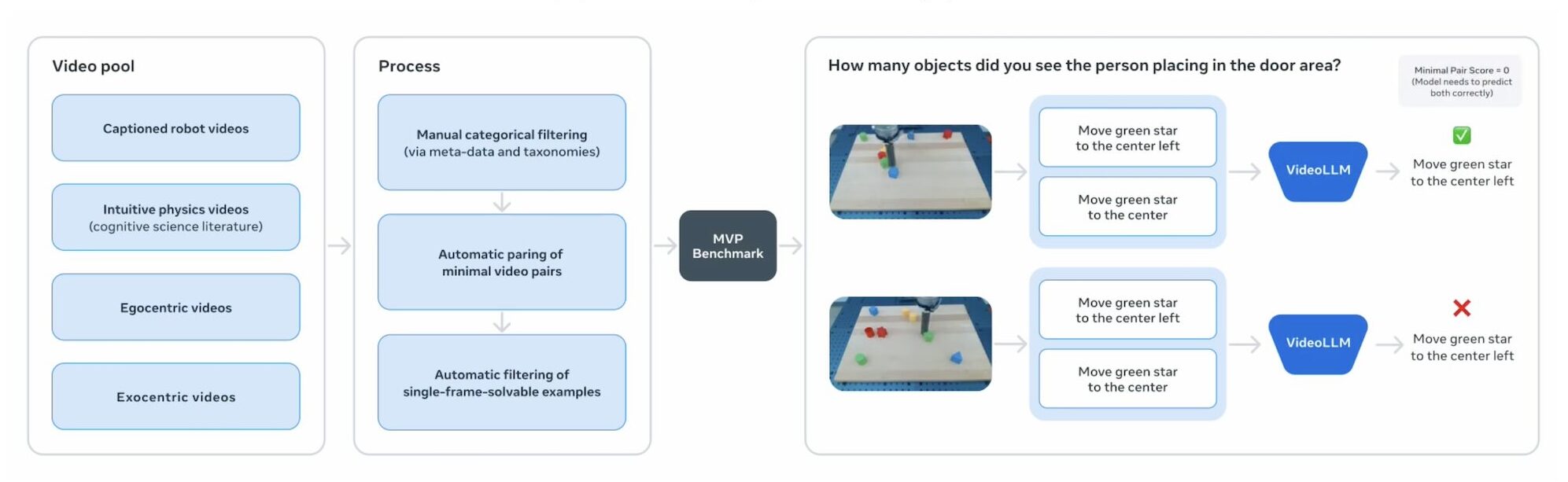
- MVPBench: examinations whether designs count on real understanding instead of dataset faster ways in video clip question-answering.
- CausalVQA: checks out thinking regarding cause-and-effect, expectancy, and counterfactuals.
The V-JEPA 2 code and design checkpoints are offered for industrial and study usage, with Meta intending to urge more comprehensive expedition of globe designs in robotics and symbolized AI.
Meta signs up with various other technology leaders in creating their very own globe designs. Google DeepMind has actually been creating its very own variation, Genie, which can replicate whole 3D atmospheres. And Globe Labs, a start-up started by Fei-Fei Li, elevated $230 million to develop big globe designs.
发布者:Robot Talk,转转请注明出处:https://robotalks.cn/meta-v-jepa-2-world-model-uses-raw-video-to-train-robots/