


The Vidar symbolized AI design from ShengShu utilizes substitute globes rather than physical training information. Resource: Adobe Supply, Vectorhub by ice
ShengShu Modern technology Co. the other day introduced its multi-view physical AI training design, Vidar– which represents for “video clip diffusion for activity thinking.” Making use of Vidu’s capacities in semantic and video clip understanding, Vidar utilizes a minimal collection of physical information to mimic a robotic’s decision-making in real-world settings, claimed the business.
” Vidar provides a drastically various technique to training symbolized AI designs,” specified ShengShu Modern technology. “Equally as Tesla concentrates on vision-based training and Waymo leans right into lidar, the market is checking out different courses to physical AI.”
Established In March 2023, ShengShu Modern technology focuses on the advancement of multimodal huge language designs (LLMs). The Beijing-based business claimed it supplies mobility-as-a-service (MaaS) and software-as-a-service (SaaS) items for smarter, much faster, and much more scalable web content production.
With its front runner video-generation system Vidu, ShengShu claimed it has actually gotten to customers in greater than 200 nations and areas around the globe, covering areas consisting of interactive amusement, advertising and marketing, movie, computer animation, social tourist, and much more.
Vidar substitute training to speed up robotic advancement
” While some business educate physical AI by installing designs right into real-world robotics and accumulating information with the physical communications that their robotics experience, it’s a technique that’s pricey, hardware-dependent, and tough to range,” claimed ShengShu Modern technology. “Others depend on totally substitute training, however this frequently does not have the irregularity and edge-case information required for real-world release.”
Vidar takes a various technique, the business declared. It incorporates minimal physical training information with generative video clip to make forecasts and create brand-new theoretical situations, developing a multi-view simulation including natural training settings, all within an online room. This permits even more durable, scalable training without the moment, expense, or constraints of physical-world information collection, described ShengShu.
Improved top of the Vidu generative video clip design, Vidar can carry out dual-arm control jobs with multi-view video clip forecast and also reply to natural-language voice commands after fine-tuning. The design properly functions as an electronic mind for real-world activity, claimed the business.
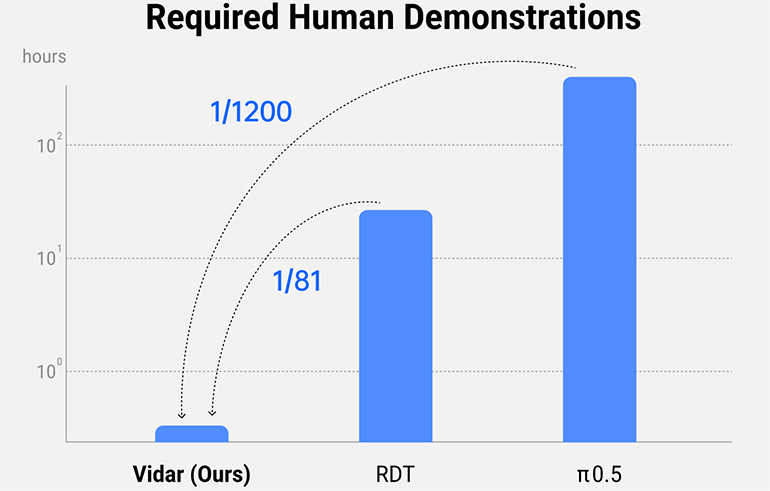
Making use of Vidu’s generative video clip engine, Vidar creates large simulations to decrease reliance on physical information, while preserving the intricacy and splendor required to educate real-world-capable AI representatives. ShengShu claimed Vidar can theorize a generalised collection of robot activities and jobs from just 20 mins of training information. The business insisted that is in between 1/80 and 1/1,200 of the information required to educate industry-leading designs consisting of RDT and π0.5.
ShengShu claimed Vidar’s core development hinges on its modular two-stage discovering style. Unlike typical approaches that combine assumption and control, Vidar decouples them right into 2 distinctive phases for higher adaptability and scalability.
In the upstream phase, large basic video clip information and moderate-scale symbolized video clip information are utilized to educate Vidu’s design for affective understanding.
In the 2nd downstream phase, a task-agnostic design called AnyPos transforms that aesthetic understanding right into workable electric motor commands for robotics. This splitting up makes it considerably less complicated and faster to educate and release AI throughout various kinds of robotics, while reducing expenses and enhancing scalability.
Vidar is developed to decrease the quantity of training information required to educate AI designs. Resource: ShengShu Innovation.
Vidar a structure for scalable symbolized knowledge
Vidar adheres to a scalable training structure influenced by language and picture structure designs of the previous years of AI advancements. ShengShu claimed its three-tiered information pyramid, covering large common video clip, symbolized video clip information, and robot-specific instances, creates a much more versatile system, decreasing typical information traffic jam.
Improved the U-ViT style, which discovers the combination of diffusion designs and transformer designs for a large variety of multimodal generation jobs, Vidar utilizes lasting temporal modeling and multi-angle video clip uniformity to power literally based decision-making.
This layout sustains fast transfer from simulation to real-world release, which ShengShu claimed is crucial for robotics in vibrant settings. It likewise reduces design intricacy, according to the business,
ShengShu claimed Vidar can promote robotics fostering throughout numerous fields. From home aides and eldercare to clever production and clinical robotics, the design makes it possible for quickly adjustment to brand-new settings and multi-task situations, all with very little information, it included.
Vidar develops an AI-native course for robotics advancement that is reliable, scalable, and affordable, ShengShu declared. By changing basic video clip right into workable robot knowledge, the business claimed its design can link the space in between aesthetic understanding and symbolized company.

Vidar has a modular discovering style. Resource: ShengShu Innovation
ShengShu marks turning points in multimodal AI
Vidar improves the fast energy of the Vidu video clip structure design, claimed ShengShu. The business noted data given that its launching:
- Vidu got to 1 million customers within one month
- Exceeded 10 million customers in simply 3 months
- Created over 100 million video clips by Month 4
- Reference-to-video generation surpassed 100 million by Month 8
- Complete created video clips currently leading 300 million
ShengShu remains to increase the frontiers of multimodal AI, Vidar stands for the following frontier– bringing generalization, generativity, and personification right into one unified system.
Editor’s note: RoboBusiness 2025, which will certainly get on Oct. 15 and 16 in Santa Clara, Calif., will certainly consist of tracks on physical AI and humanoid robotics. Enrollment is currently open.

The article ShengShu Modern technology introduces Vidar multi-view physical AI training design showed up initially on The Robotic Record.
发布者:Robot Talk,转转请注明出处:https://robotalks.cn/shengshu-technology-launches-vidar-multi-view-physical-ai-training-model/