

By Andre He, Vivek Myers
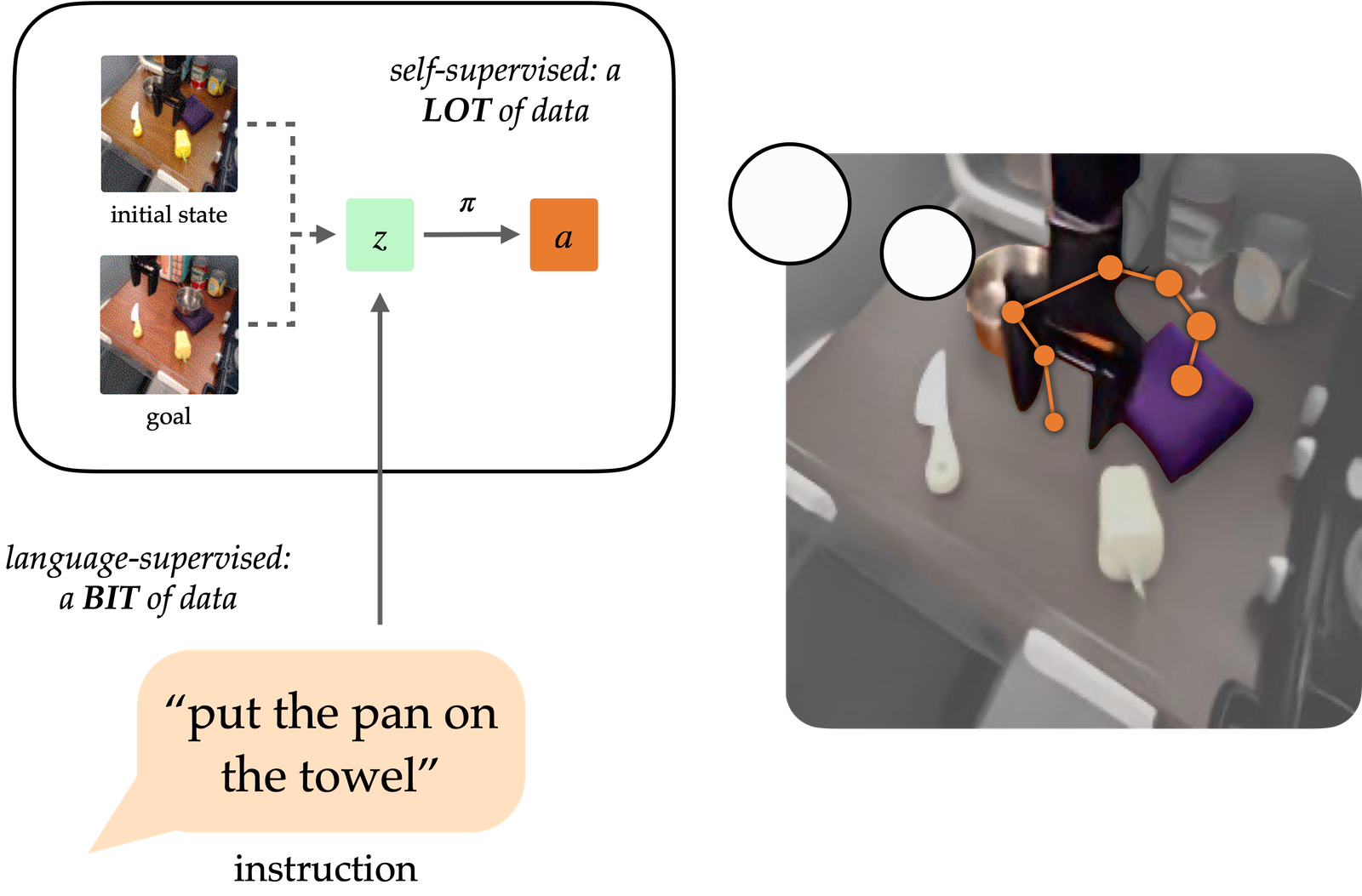
A historical objective of the area of robotic understanding has actually been to produce generalist representatives that can execute jobs for people. All-natural language has the prospective to be a user friendly user interface for people to define approximate jobs, however it is hard to educate robotics to adhere to language directions. Techniques like language-conditioned behavior cloning (LCBC) train plans to straight copy professional activities conditioned on language, however call for people to annotate all training trajectories and generalise inadequately throughout scenes and habits. On the other hand, current goal-conditioned strategies execute better at basic adjustment jobs, however do not allow simple job spec for human drivers. Exactly how can we fix up the convenience of defining jobs via LCBC-like strategies with the efficiency renovations of goal-conditioned understanding?
Conceptually, an instruction-following robotic needs 2 capacities. It requires to ground the language direction in the physical atmosphere, and afterwards have the ability to accomplish a series of activities to finish the designated job. These capacities do not require to be found out end-to-end from human-annotated trajectories alone, however can rather be found out independently from the proper information resources. Vision-language information from non-robot resources can assist discover language basing with generalization to varied directions and aesthetic scenes. On the other hand, unlabeled robotic trajectories can be utilized to educate a robotic to get to certain objective states, also when they are not connected with language directions.
Conditioning on aesthetic objectives (i.e. objective photos) offers corresponding advantages for plan understanding. As a kind of job spec, objectives are preferable for scaling since they can be easily created knowledge relabeling (any kind of state got to along a trajectory can be an objective). This permits plans to be educated through goal-conditioned behavior cloning (GCBC) on huge quantities of unannotated and disorganized trajectory information, consisting of information gathered autonomously by the robotic itself. Objectives are likewise simpler to ground because, as photos, they can be straight contrasted pixel-by-pixel with various other states.
Nonetheless, objectives are much less user-friendly for human customers than all-natural language. For the most part, it is simpler for an individual to define the job they desire done than it is to give an objective photo, which would likely call for doing the job anyways to produce the photo. By subjecting a language user interface for goal-conditioned plans, we can integrate the staminas of both objective- and language- job spec to allow generalist robotics that can be conveniently regulated. Our technique, reviewed listed below, reveals such a user interface to generalise to varied directions and scenes making use of vision-language information, and enhance its physical abilities by absorbing huge disorganized robotic datasets.
Objective depictions for direction complying with

The GRIF design contains a language encoder, an objective encoder, and a plan network. The encoders specifically map language directions and objective photos right into a common job depiction area, which conditions the plan network when anticipating activities. The design can efficiently be conditioned on either language directions or objective photos to anticipate activities, however we are mainly making use of goal-conditioned training as a method to enhance the language-conditioned usage situation.
Our method, Objective Representations for Guideline Adhering To (GRIF), collectively educates a language- and an objective- conditioned plan with straightened job depictions. Our essential understanding is that these depictions, straightened throughout language and objective techniques, allow us to efficiently integrate the advantages of goal-conditioned understanding with a language-conditioned plan. The found out plans are after that able to generalise throughout language and scenes after training on mainly unlabeled demo information.
We educated GRIF on a variation of the Bridge-v2 dataset consisting of 7k identified demo trajectories and 47k unlabeled ones within a kitchen area adjustment setup. Because all the trajectories in this dataset needed to be by hand annotated by people, having the ability to straight utilize the 47k trajectories without note dramatically enhances effectiveness.
To pick up from both kinds of information, GRIF is educated collectively with language-conditioned behavior cloning (LCBC) and goal-conditioned behavior cloning (GCBC). The identified dataset has both language and objective job specs, so we utilize it to monitor both the language- and goal-conditioned forecasts (i.e. LCBC and GCBC). The unlabeled dataset has just objectives and is utilized for GCBC. The distinction in between LCBC and GCBC is simply an issue of picking the job depiction from the matching encoder, which is entered a common plan network to anticipate activities.
By sharing the plan network, we can anticipate some renovation from making use of the unlabeled dataset for goal-conditioned training. Nonetheless, GRIF allows a lot more powerful transfer in between both techniques by identifying that some language directions and objective photos define the exact same actions. Specifically, we manipulate this framework by needing that language- and objective- depictions be comparable for the exact same semantic job. Thinking this framework holds, unlabeled information can likewise profit the language-conditioned plan because the objective depiction estimates that of the missing out on direction.
Positioning via contrastive understanding
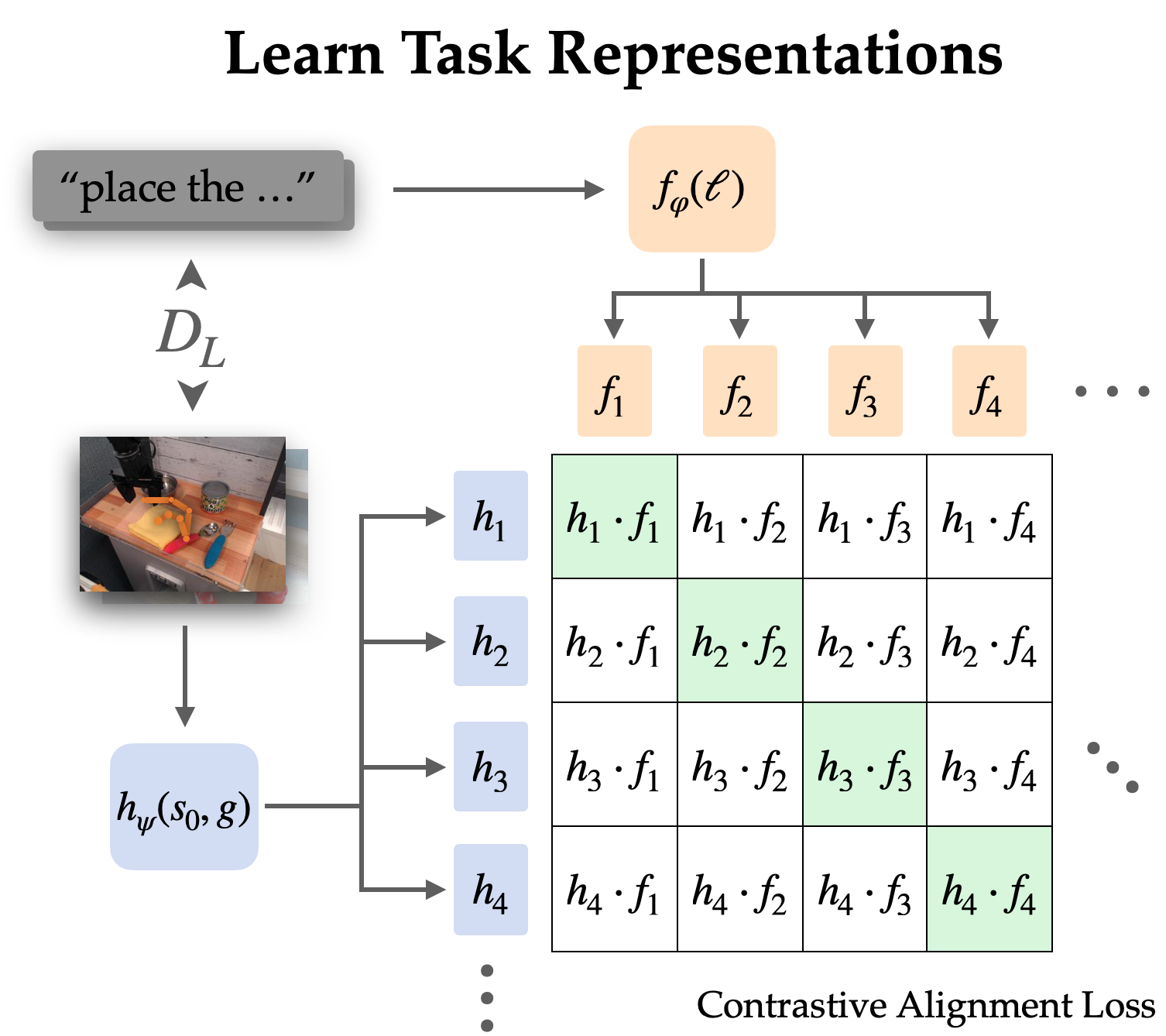
We clearly line up depictions in between goal-conditioned and language-conditioned jobs on the identified dataset via contrastive understanding.
Because language typically defines family member adjustment, we select to line up depictions of state-goal couple with the language direction (instead of simply objective with language). Empirically, this likewise makes the depictions simpler to discover because they can leave out most details in the photos and concentrate on the adjustment from state to objective.
We discover this positioning framework via an infoNCE goal on directions and photos from the identified dataset. We educate double photo and message encoders by doing contrastive understanding on matching sets of language and objective depictions. The unbiased urges high resemblance in between depictions of the exact same job and reduced resemblance for others, where the adverse instances are tasted from various other trajectories.
When making use of ignorant adverse tasting (attire from the remainder of the dataset), the found out depictions typically neglected the real job and merely straightened directions and objectives that described the exact same scenes. To utilize the plan in the real life, it is not really beneficial to associate language with a scene; instead we require it to disambiguate in between various jobs in the exact same scene. Hence, we utilize a tough adverse tasting method, where approximately half the downsides are tasted from various trajectories in the exact same scene.
Normally, this contrastive understanding configuration teases at pre-trained vision-language versions like CLIP. They show efficient zero-shot and few-shot generalization ability for vision-language jobs, and use a method to integrate expertise from internet-scale pre-training. Nonetheless, most vision-language versions are developed for lining up a solitary fixed photo with its inscription without the capacity to comprehend adjustments in the atmosphere, and they choke up when needing to focus on a solitary item in messy scenes.
To attend to these concerns, we design a system to suit and make improvements CLIP for lining up job depictions. We change the CLIP design to ensure that it can operate a set of photos integrated with very early blend (piled channel-wise). This ends up being a qualified initialization for inscribing sets of state and objective photos, and one which is especially proficient at protecting the pre-training take advantage of CLIP.
Robotic plan outcomes
For our primary outcome, we assess the GRIF plan in the real life on 15 jobs throughout 3 scenes. The directions are selected to be a mix of ones that are well-represented in the training information and unique ones that call for some level of compositional generalization. Among the scenes likewise includes a hidden mix of things.
We contrast GRIF versus simple LCBC and more powerful standards motivated by previous job like LangLfP andBC-Z LLfP represents collectively educating with LCBC and GCBC. BC-Z is an adjustment of the name technique to our setup, where we educate on LCBC, GCBC, and a straightforward positioning term. It maximizes the cosine range loss in between the job depictions and does not utilize image-language pre-training.
The plans were vulnerable to 2 primary failing settings. They can fall short to comprehend the language direction, which causes them trying one more job or doing no beneficial activities whatsoever. When language grounding is not durable, plans could also begin an unplanned job after having actually done the appropriate job, because the initial direction runs out context.
Instances of basing failings

” placed the mushroom in the steel pot”

” placed the spoon on the towel”

” placed the yellow bell pepper on the fabric”

” placed the yellow bell pepper on the fabric”
The various other failing setting is falling short to adjust things. This can be because of missing out on a grip, relocating imprecisely, or launching things at the inaccurate time. We keep in mind that these are not integral drawbacks of the robotic configuration, as a GCBC plan educated on the whole dataset can regularly do well in adjustment. Instead, this failing setting normally shows an inefficacy in leveraging goal-conditioned information.
Instances of adjustment failings

” relocate the bell pepper to the left of the table”

” placed the bell pepper in the frying pan”

” relocate the towel beside the microwave”
Contrasting the standards, they each dealt with these 2 failing settings to various levels. LCBC counts only on the little identified trajectory dataset, and its bad adjustment ability avoids it from finishing any kind of jobs. LLfP collectively educates the plan on identified and unlabeled information and reveals dramatically boosted adjustment ability from LCBC. It attains practical success prices for usual directions, however falls short to ground much more intricate directions. BC-Z’s positioning method likewise enhances adjustment ability, likely since positioning enhances the transfer in between techniques. Nonetheless, without exterior vision-language information resources, it still battles to generalise to brand-new directions.
GRIF reveals the most effective generalization while likewise having solid adjustment capacities. It has the ability to ground the language directions and accomplish the job also when several distinctive jobs are feasible in the scene. We reveal some rollouts and the matching directions listed below.
Plan Rollouts from GRIF

” relocate the frying pan to the front”

” placed the bell pepper in the frying pan”

” placed the blade on the purple fabric”

” placed the spoon on the towel”
Final Thought
GRIF allows a robotic to use huge quantities of unlabeled trajectory information to discover goal-conditioned plans, while supplying a “language user interface” to these plans through straightened language-goal job depictions. As opposed to prior language-image positioning approaches, our depictions line up adjustments in state to language, which we reveal brings about substantial renovations over conventional CLIP-style image-language positioning goals. Our experiments show that our method can efficiently utilize unlabeled robot trajectories, with huge renovations in efficiency over standards and approaches that just utilize the language-annotated information
Our technique has a variety of constraints that might be attended to in future job. GRIF is not appropriate for jobs where directions state even more concerning just how to do the job than what to do (e.g., “put the water gradually”)– such qualitative directions could call for various other kinds of positioning losses that think about the intermediate actions of job implementation. GRIF likewise presumes that all language grounding originates from the part of our dataset that is completely annotated or a pre-trained VLM. An amazing instructions for future job would certainly be to prolong our positioning loss to use human video clip information to discover abundant semiotics from Internet-scale information. Such a method might after that utilize this information to enhance basing on language outside the robotic dataset and allow extensively generalizable robotic plans that can adhere to customer directions.
This blog post is based upon the complying with paper:
-
Goal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
Vivek Myers *, Andre He *, Kuan Fang, Homer Walke, Philippe Hansen-Estruch, Ching-An Cheng, Mihai Jalobeanu, Andrey Kolobov, Anca Dragan, and Sergey Levine
.
发布者:BAIR Blog,转转请注明出处:https://robotalks.cn/goal-representations-for-instruction-following-2/